目录
一、原理与目的
1、线性回归基于两个的假设:
2、线性回归的优缺点:
3、线性回归的主要目的是:
二、损失函数(loss function)
1、平方误差损失函数(忽略了噪声误差)
2、均方误差损失函数
三、随机梯度下降(通过不断地在损失函数递减的方向上更新参数来降低误差。)
四、代码实现
参考文章:
机器学习—线性回归算法(Linear Regression)-CSDN博客
《动手学深度学习》 — 动手学深度学习 2.0.0 documentation (d2l.ai)
4.机器学习-十大算法之一线性回归算法(LinearRegression)案例讲解-CSDN博客
在介绍之前,有几个概念:
假如要根据一个包含道路曲率(Curvature)、车速(Velocity)、侧向加速度(Ay)和方向盘转角(Steering_Angle)真实的数据集去预测未来的方向盘转角。
(1)数据集(data set): 一般来说,一个完整的数据集应该包括训练集、测试集和验证集。通常,数据集会被划分为训练集和测试集,比如将数据集的70%用作训练集,30%用作测试集。在进行训练时,可以使用交叉验证的方法将训练集再次划分为训练子集和验证子集,用于模型的训练和验证。
- 训练集:用于训练机器学习模型的数据集。模型通过学习训练集中的数据特征和规律,来构建预测或分类的模型。
- 测试集:用于评估机器学习模型性能的数据集。通过将模型应用于测试集,可以衡量模型的准确性、鲁棒性等性能指标。
- 验证集(可选):在训练过程中,用于调整模型参数和选择最佳模型的数据集。验证集可以帮助我们在训练过程中避免过拟合或欠拟合的问题。
(2)标签(label)或目标(target):预测的目标(因变量),即预测方向盘转角
(3)特征(feature)或协变量(covariate):预测所依据的自变量,即道路曲率、车速和侧向加速度
时间序列预测中的线性回归是一种常用的方法,它基于时间序列数据之间的线性关系进行预测。以下是对时间序列预测中线性回归的详细解释:
一、原理与目的
1、线性回归基于两个的假设:
- 线性关系假设:
- 内容:自变量 x(一个或多个)和因变量 y 之间的关系是线性的。这意味着,存在一个或多个系数(包括一个常数项或截距),使得 y 可以表示为 x 的线性函数。
- 数学表达:对于单变量线性回归,可以表示为 y=W1x+b+ϵ,其中W1 是权重,b是偏置,ϵ 是误差项。对于多变量线性回归,则形式为 y=W1x1+W1x2+⋯+Wnxn+b+ϵ。
- 正态分布假设(或称为误差项的正态分布):
- 内容:任何噪声(即误差项 ϵ)都遵循正态分布(也称为高斯分布)。这意味着误差项是随机的,且其分布是对称的,有一个均值(通常为零)和一个方差。
- 数学表达:误差项 ϵ 服从正态分布,即 ϵ∼N(0,σ2),其中 σ2 是方差。
2、线性回归的优缺点:
-
优势
- 线性回归模型简单明了,易于理解和实现。
- 线性回归的计算过程相对简单,计算效率高,可以快速得到预测结果。
-
缺点
- 线性回归只能处理线性关系,对于非线性关系的数据可能效果不佳。
- 线性回归没有考虑时间序列数据中的时间依赖性,因此在处理序列数据时可能表现不佳。
3、线性回归的主要目的是:
找到一组权重向量w和偏置b,拟合一个线性模型,当给定新的x时,这组权重向量和偏置能够使得新样本预测对应的 y 值。
在开始寻找最好的模型参数(model parameters)w和b之前,我们还需要两个东西:
(1)一种模型质量的度量方式——损失函数;
(2)一种能够更新模型以提高模型预测质量的方法——随机梯度下降。
二、损失函数(loss function)
损失函数(loss function)能够量化目标的实际值与预测值之间的差距。通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。
1、平方误差损失函数(忽略了噪声误差)
回归问题中最常用的损失函数是平方误差函数。
当样本i的预测值为ˆy(i),其相应的真实标签为y(i)时,平方误差可以定义为以下公式:

其中,常数1/2其实是没什么用的,只是这样在形式上稍微简单一些(当对损失函数求导后常数系数为1)
为了度量模型在整个数据集上的质量,需计算在训练集n个样本上的损失均值(也等价于求和)。

最后就是,找一组参数(w∗, b∗),这组参数能最小化L(w, b).
2、均方误差损失函数
均方误差损失函数(简称均方损失)可以用于线性回归的一个原因是:假设了观测中包含噪声,其中噪声服从正态分布


这里用到极大似然估计法,单个数据y的似然:

整个数据集的似然:
![]()
最后就是确定参数w和b是使整个数据集的似然最大。
化解一下
第一项没有参数w和b,最终是求w和b使第二项的值最小。
三、随机梯度下降(通过不断地在损失函数递减的方向上更新参数来降低误差。)
梯度下降最简单的用法是计算损失函数(数据集中所有样本的损失均值)关于模型参数的导数(在这里也可以称为梯度)。但因为每一次必须遍历整个数据集,执行可能会非常慢。因此,通常在每次计算更新时随机抽取一小批量B样本。
具体计算过程:(这里是只针对平方误差损失函数,均方误差同理)
(1)随机抽样一个小批量B(这也称为批量大小(batch size)),
(2)计算小批量的平均损失关于模型参数(即w和b)的偏导数(也可以称为梯度)
(3)将梯度乘以一个预先确定的正数η(η表示学习率(learning rate)),并从当前参数的值(即w和b)中减掉。
公式如下:(∂表示偏导数)

这里还有四个概念:
超参数:指可以手动预先调整但不在训练过程中更新的参数,如此时的批量大小和学习率
泛化:指模型能够适应新的、未知的数据的能力。如,找到一组参数,这组参数能够在从未见过的数据上实现较低的损失,说明泛化能力较强。
矢量化:指将算法从一次操作一个数据值转换为一次操作一组数据值的过程。这一技术可以显著提高数据处理的效率。例如:计算a+b,其中a、b中各有100个值,一种是用for循环计算每一个值,一种是直接a向量和b向量相加计算,后者即矢量化。
全连接层/稠密层:每个神经元都与上一层的所有神经元相连。对于线性回归,每个输入都与每个输出(在本例中只有一个输出)相连。

四、代码实现
根据一个包含道路曲率(Curvature)、车速(Velocity)、侧向加速度(Ay)和方向盘转角(Steering_Angle)真实的数据集,去预测未来的方向盘转角。
1、先将需要的库导入
# 导入三个常用的数据处理和可视化库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 从sklearn库中导入线性回归模型
from sklearn.linear_model import LinearRegression
# 从sklearn库中导入train_test_split函数。train_test_split函数用于将数据集划分为训练集和测试集
from sklearn.model_selection import train_test_split
# 引入mean_absolute_error对线性回归进行评估
from sklearn.metrics import mean_absolute_error as mae2、编写模型主体:
# 1. 数据预处理
# 读取数据
data = pd.read_excel('input_data_20241010160240.xlsx') # 替换为你的数据文件路径
# 提取特征和标签
labels = data['Steering_Angle']
features = data[['Curvature','Ay', 'Velocity']] # 注意这里使用了列表来提取多列
# 划分训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(features,labels,test_size=0.2)
# 其中,features表示特征数据,target表示目标数据,test_size=0.2表示将20%的数据作为测试集,剩余的80%作为训练集。划分后的训练集和测试集分别赋值给变量x_train、x_test、y_train和y_test。
# 创建模型
liner = LinearRegression()
liner.fit(x_train,y_train)
# 获取权重和偏置
weights = liner.coef_
bias = liner.intercept_
# 打印权重和偏置
print(f"Weights: {weights}")
print(f"Bias: {bias}")
# 预测
y_pred = liner.predict(x_test)
# 得分(R^2 score),回归的得分一般表示模型对数据的拟合程度,越接近1越好
score = liner.score(x_test, y_test)
print(f"R^2 score: {score}")
# 评估指标
# 计算线性回归模型在测试集上的平均绝对误差(Mean Absolute Error,MAE) ,平均绝对误差越小,模型的预测精度越高。
mae = mae(y_test, y_pred)
print(f"Mean Absolute Error: {mae}")
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimSun'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 绘制实际值和预测值的对比图
plt.figure(figsize=(10, 6))
plt.plot(range(len(y_test)), y_test, label='实际值', color='blue')
plt.plot(range(len(y_pred)), y_pred, label='预测值', color='red')
plt.xlabel('样本索引')
plt.ylabel('Steering Angle')
plt.title('实际值与预测值对比图')
plt.legend()
plt.grid(True)
plt.show()
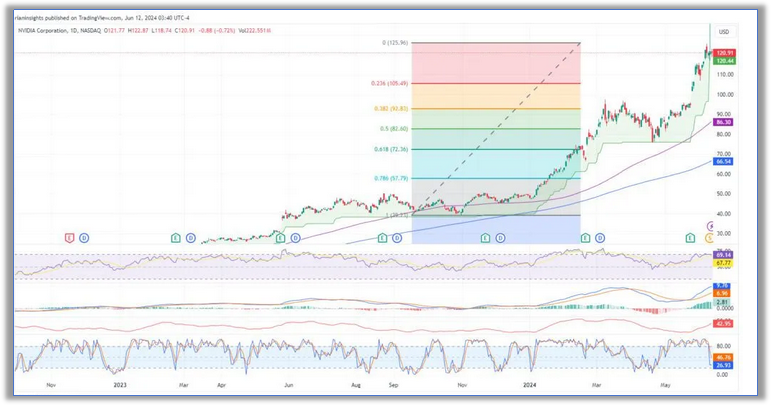
3、输出结果:(可以看到训练效果比较好,因为毕竟侧向加速度和方向盘转角有直接的关系)
至此结束。
别忘了给这篇文章点个赞哦,非常感谢。我也正处于学习的过程,如果有问题,欢迎在评论区留言讨论,一起学习!













![[红队apt]文件捆绑攻击流程](https://i-blog.csdnimg.cn/direct/f1c4d18eb5774dd08321202824c07876.png)